Logical Computer Setup#
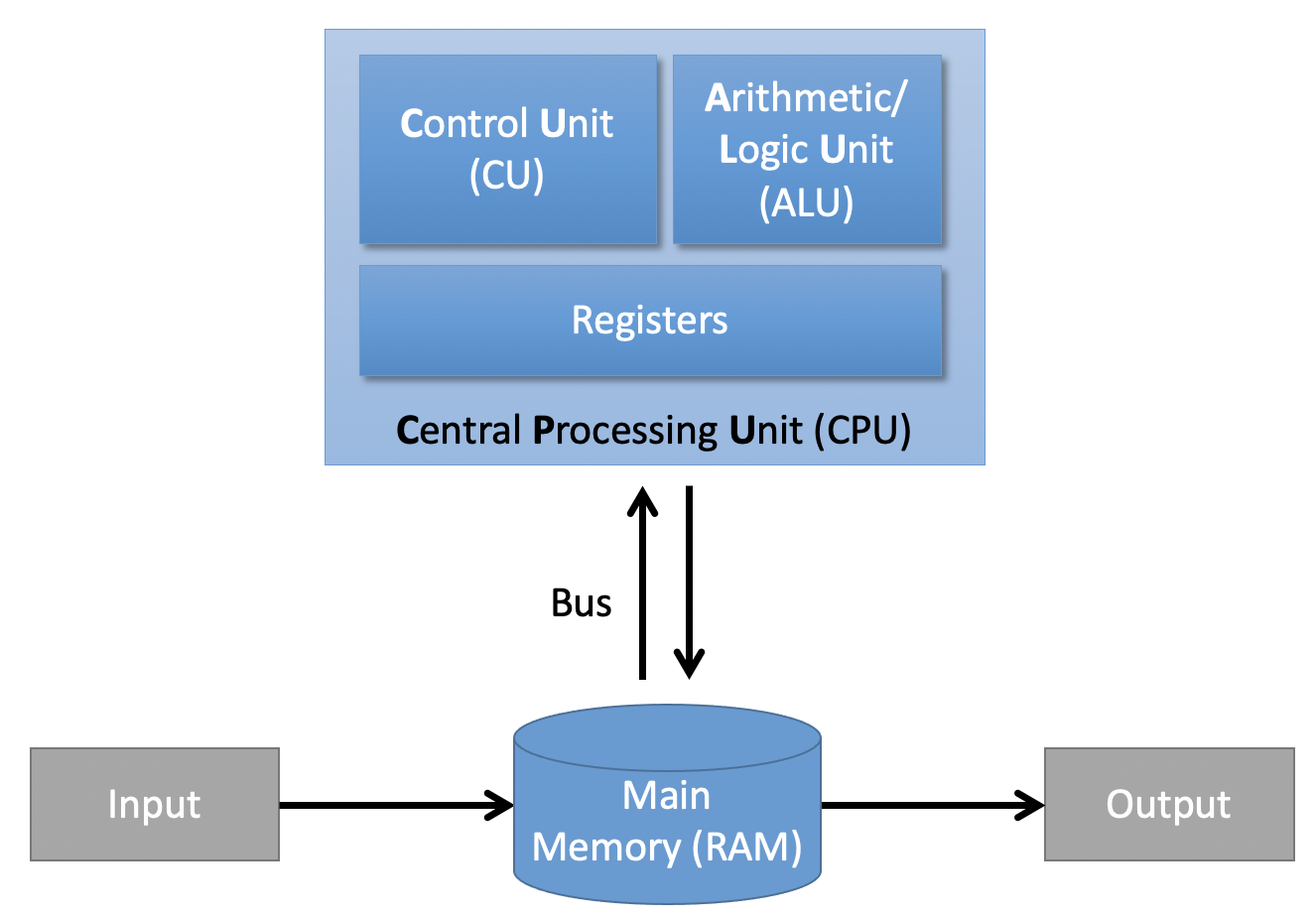
The Von-Neumann Architecture (1945)#
The von Neumann architecture — also known as the von Neumann model or Princeton architecture — is a computer architecture proposed by John von Neumann and others in 1945. The document describes a design architecture for an electronic digital computer with these components:
A processing unit with both an arithmetic logic unit and processor registers
A control unit that includes an instruction register and a program counter
Memory that stores data and instructions
External mass storage
Input and output mechanisms
Metrics for hardware performance#
Transfer rate [bytes/s]: Speed at which data travels from one location to another
![]()

Source: ASPP/MemoryBoundComputations
Latency [s]: Time between data is requested and data is available.
Clock rate [Giga Hertz]: Number of clock cycles a CPU or RAM performs per second. -> „processor speed“


Source: ASPP/MemoryBoundComputations
Von-Neumann Bottleneck#
The shared bus between the program memory and data memory leads to the von Neumann bottleneck, the limited throughput (data transfer rate) between the central processing unit (CPU) and memory compared to the amount of memory. Because the single bus can only access one of the two classes of memory at a time, throughput is lower than the rate at which the CPU can work. This seriously limits the effective processing speed when the CPU is required to perform minimal processing on large amounts of data. The CPU is continually forced to wait for needed data to move to or from memory. Since CPU speed and memory size have increased much faster than the throughput between them, the bottleneck has become more of a problem, a problem whose severity increases with every new generation of CPU. (Wikipedia)
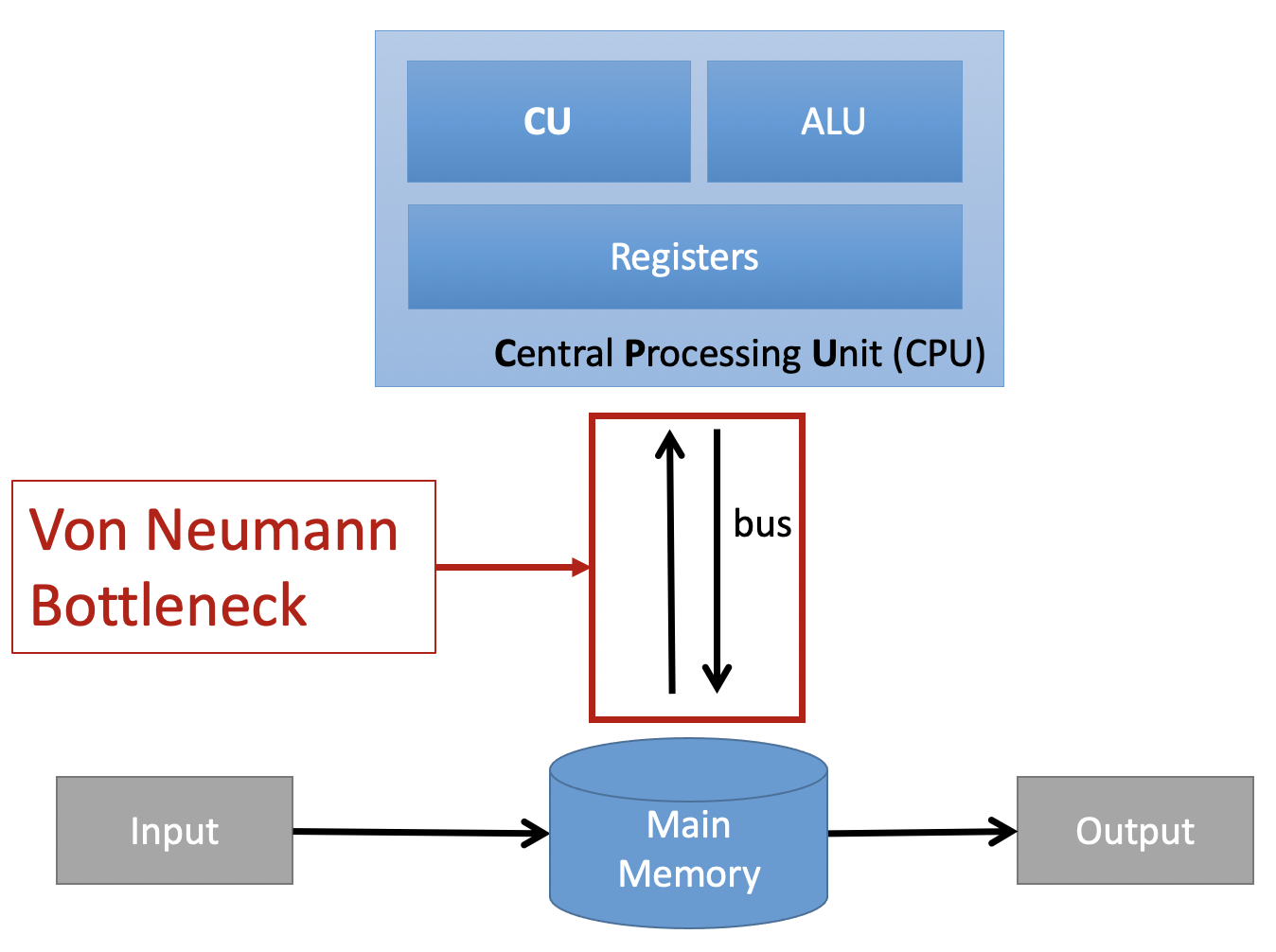
Source: Own figure
Strategies to overcome the Von-Neumann Bottleneck#
MIMD: Multiple Instruction, Multiple Data#
In computing, multiple instruction, multiple data (MIMD) is a technique employed to achieve parallelism. Machines using MIMD have a number of processor cores that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data. (Wikipedia)
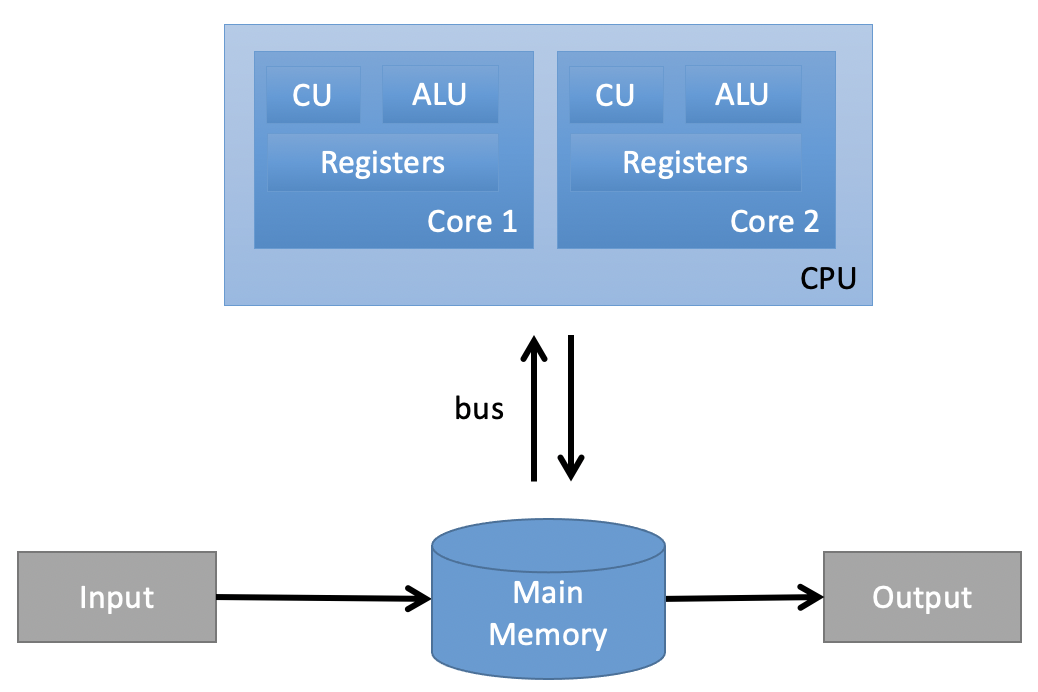
Source: Own figure
SIMD: Single Instruction, Multiple Data#
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. Such machines exploit data level parallelism, but not concurrency: there are simultaneous (parallel) computations, but each unit performs the exact same instruction at any given moment (just with different data). (Wikipedia)
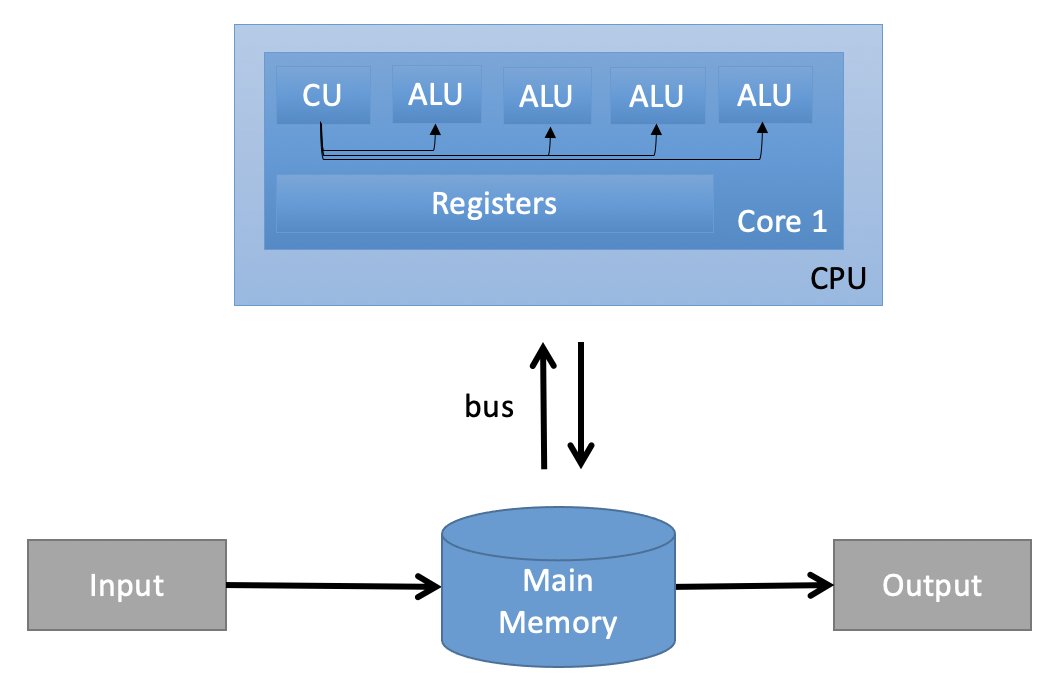
Source: Own figure
Caches#
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost (time or energy) to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels (L1, L2, often L3, and rarely even L4), with different instruction-specific and data-specific caches at level 1. (Wikipedia)
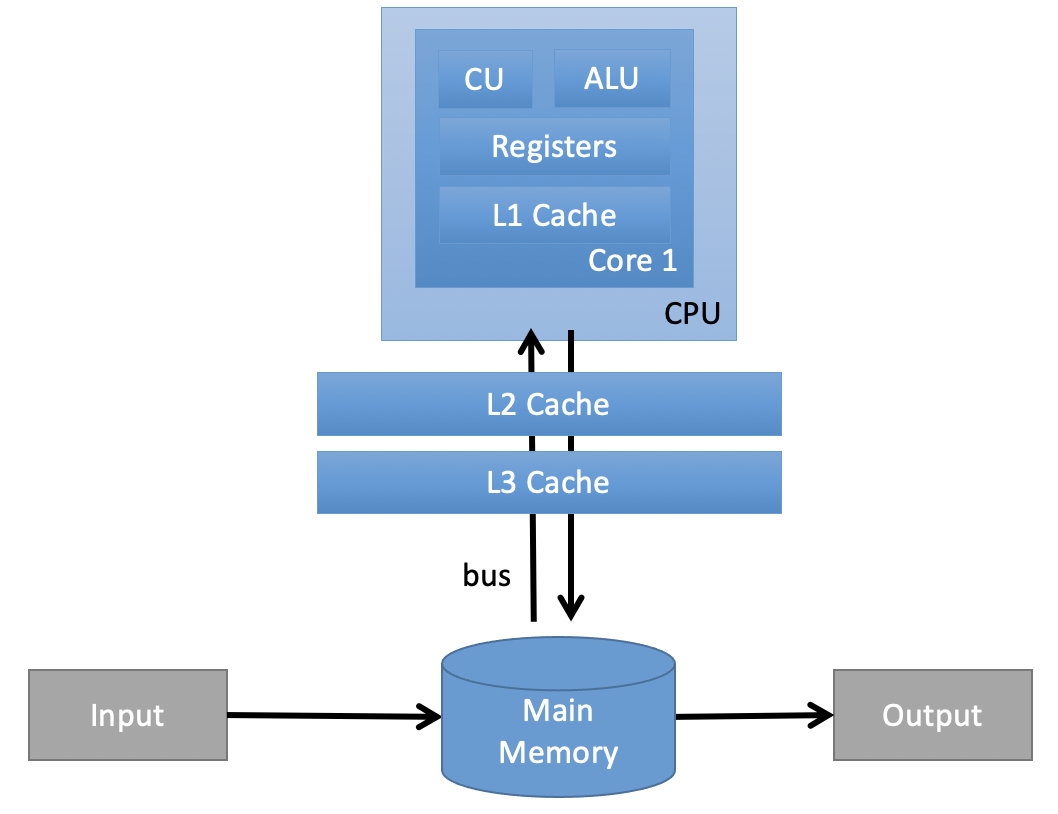
Source: Own figure
Computer memory hierarchy#
In computer organisation, the memory hierarchy separates computer storage into a hierarchy based on response time. Since response time, complexity, and capacity are related, the levels may also be distinguished by their performance and controlling technologies.[1] Memory hierarchy affects performance in computer architectural design, algorithm predictions, and lower level programming constructs involving locality of reference. (Wikipedia)
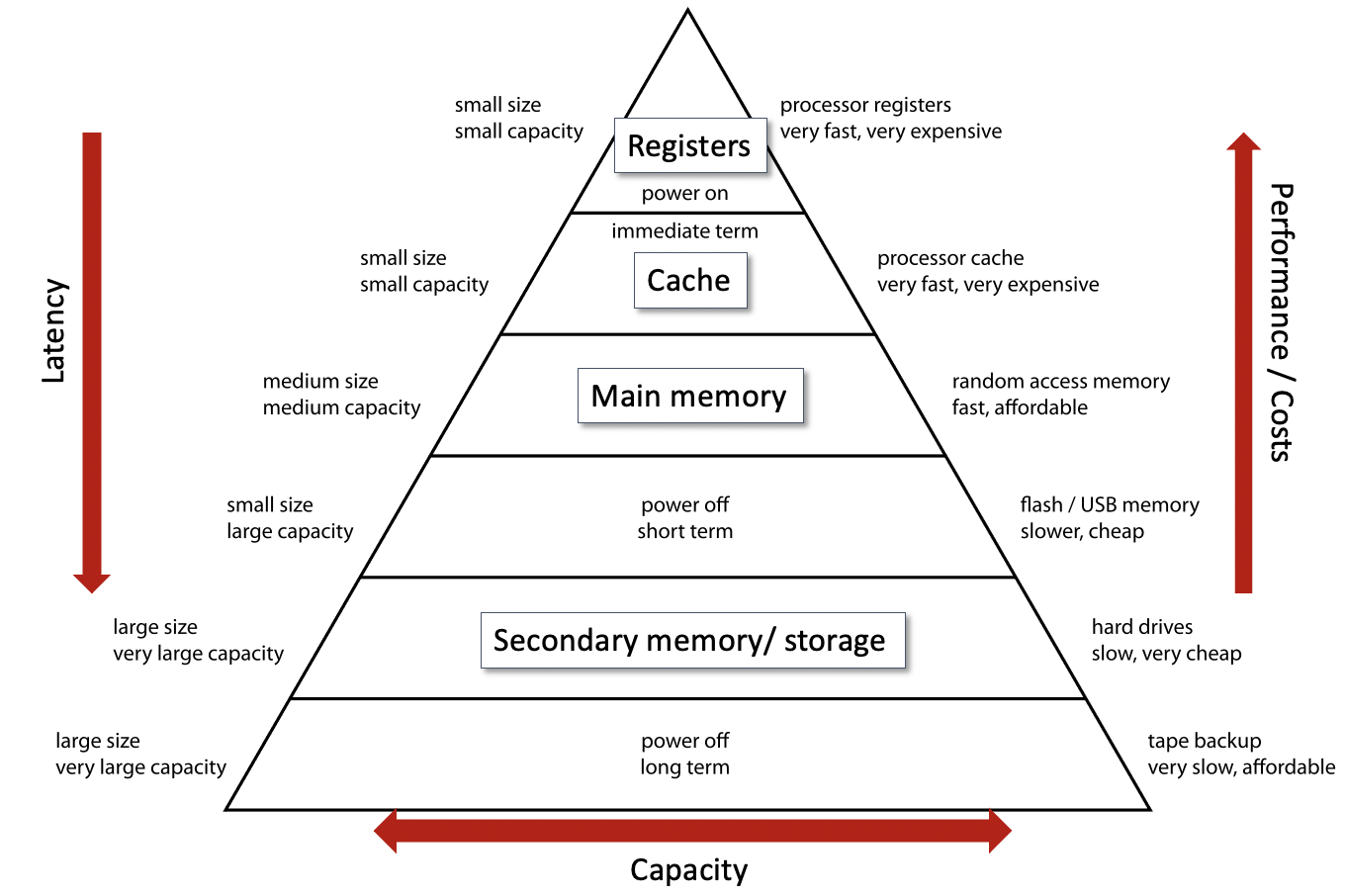
Source: Own figure, adapted based on https://en.wikipedia.org/wiki/Memory_hierarchy
Conclusion#
Extending hardware is not always an option to speed up data processing
But you can use software and write your scripts so that it optimally uses your hardware
Numpy, pandas and other packages already help you a lot by optimizing operations in the background, e.g. by using Basic Linear Algebra Subprograms (BLAS).
Still, you just need to use them wisely!
References#
Schmidt, B., Gonzalez-Dominguez, J., Hundt, C., & Schlarb, M. (2017). Parallel programming: concepts and practice. Morgan Kaufmann. Google Books
Micha Gorelick, Ian Ozsvald. High Performance Python. O’Reilly, 2014. (Available via Uni HD)
Video: Factors Affecting CPU Performance (Clock Speed, Cache & Multiple-Cores)
von Neumann, John (1945), First Draft of a Report on the EDVAC (PDF), archived from the original (PDF) on March 14, 2013, retrieved August 24, 2011.